
부하테스트 예측 검증
부하테스트 프로세스
앞서 설명한 부하테스트를 통해 개발한 예측 모형을 검증할 것이다.글 보러가기
부하테스트를 통한 데이터 생성하고, 해당 데이터를 통해 예측한 뒤 평가 지표를 통해 모형을 검증할 것이다.
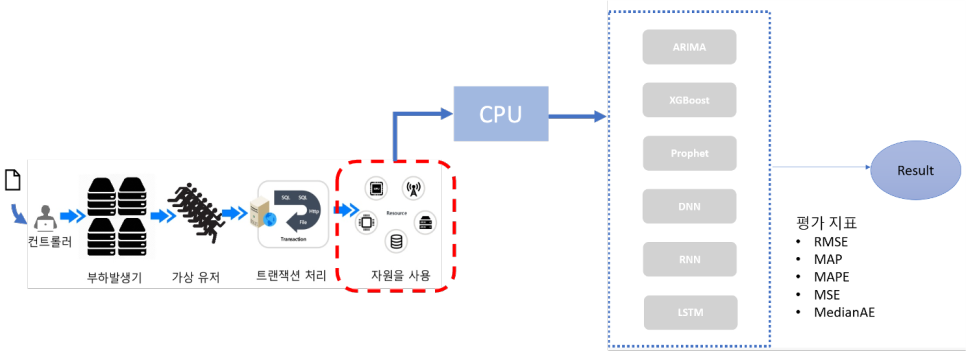
테스트 시나리오
웹 어플리케이션
→ 웹 어플리케이션을 개발한 후 해당 웹 사이트를 사용자가 접속함으로써 자원을 사용하도록 한다.
→ 화면을 띄우기 위해 데이터 조회나 유저에 의해 로그인 입력등을 통한 자원 사용이 있다.
▶ 간단한 웹 페이지 개발
→ 웹 페이지 부하 테스트 기능을 위함

HTML : 웹 페이지 출력
PHP : DB 연동
▶ Apache 웹 서버를 구축한 후 웹 페이지를 Apache 서버에 올려 테스트 진행
▶ 데이터베이스에 저장된 데이터를 Select
Jmeter 설정
→ Jmeter Server 1대, vm 3대
VM1 : 2시간 단위로 1시간 부하(평일, 주말 상관없이)
VM2 : 평일 오전
VM3 : 평일 오후
| VCPUs | RAM | SIZE | |
|---|---|---|---|
| Jmeter Server | 8 | 7.9GB | 50GB |
| VM01 | 4 | 8GB | 80GB |
| VM02 | 2 | 4GB | 40GB |
| VM03 | 2 | 4GB | 40GB |
Jmeter Server
→ 각 vm에 관한 부하 설정
→ 부하시간을 설정한 후 자동화


[자동화]
- 설정한 파일을 실행하는 스크립트 작성
- Crontab을 통한 희망하는 시간대 실행
- Log 삭제 : 디스크 문제(파일 시스템 오류) 방지 위해 로그 삭제 스크립트 추가
- 부하 발생시 로그 저장
부하 데이터 생성(vm 설정)
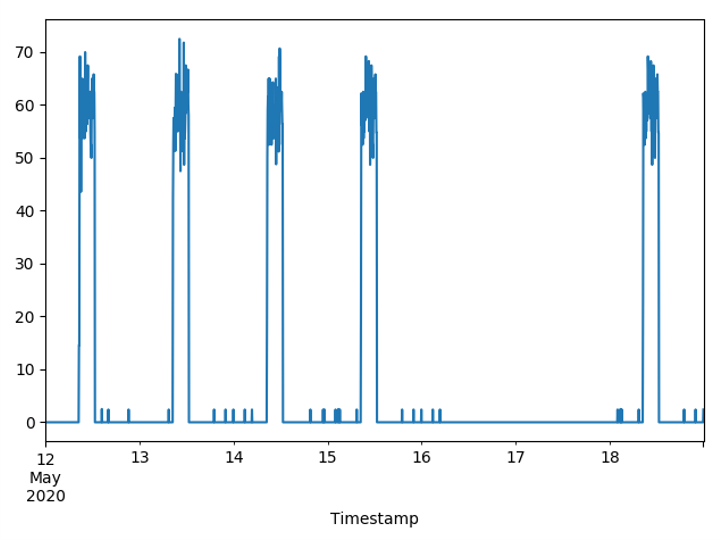
1. VM1
▶ 설정
→ 2시간마다 1시간씩 부하
→ 평일, 주말 상관없이 부하 생성
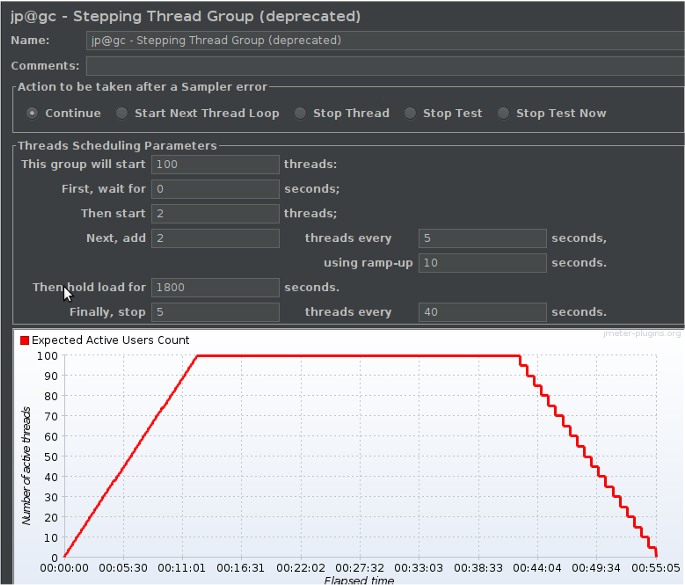
최대 100명의 접속자
2명씩 5초 유지 후 10초마다 증가
1800초(30분) 유지
40초 간격으로 5명 사용자 제거
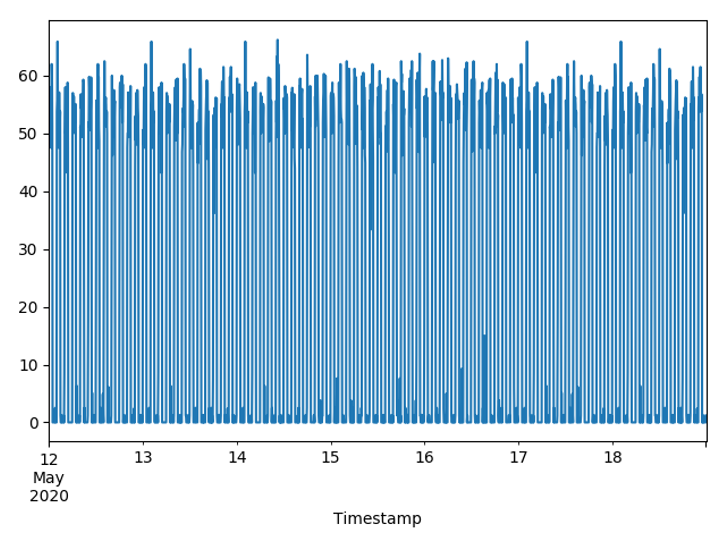
▶ 최종 데이터
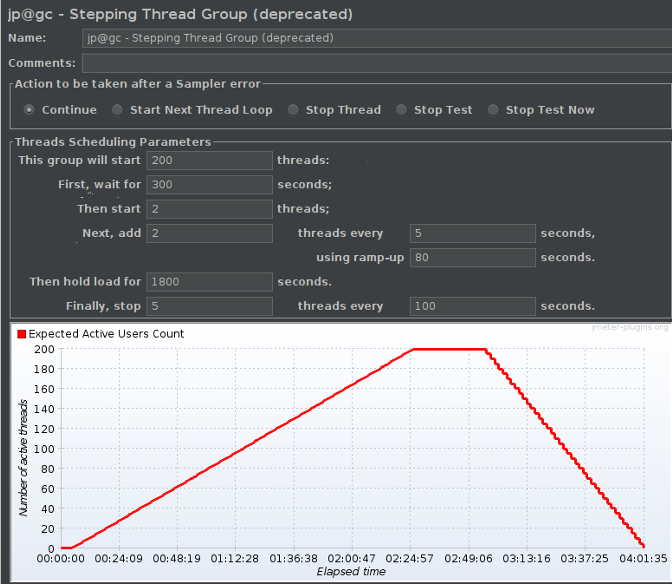
2. VM2
▶ 설정
→ 오전 시간만 부하
→ 평일 부하 생성
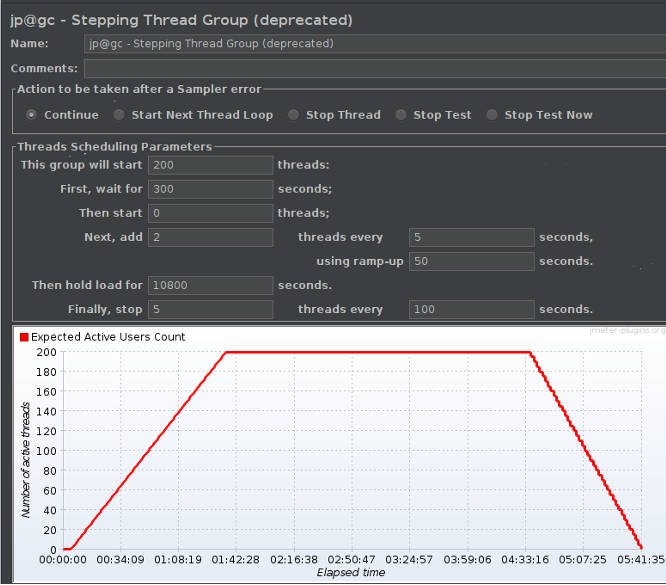
최대 200명의 접속자
2명씩 5초 유지 후 50초마다 증가
10800초(3시간) 유지
100초 간격으로 5명 사용자 제거
▶ 최종 데이터
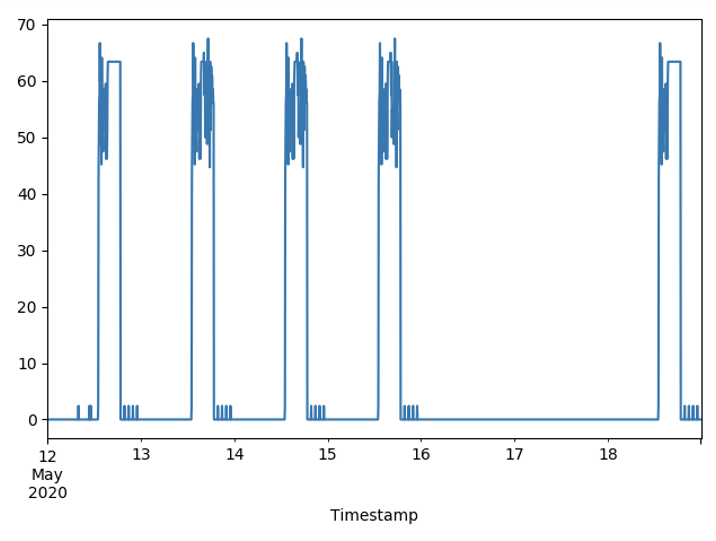
3. VM3
▶ 설정
→ 오전 시간만 부하
→ 평일 부하 생성
최대 200명의 접속자
2명씩 5초 유지 후 80초마다 증가
1800초(30분) 유지
100초 간격으로 5명 사용자 제거
▶ 최종 데이터
예측 모형 검증
단일 예측(CPU)
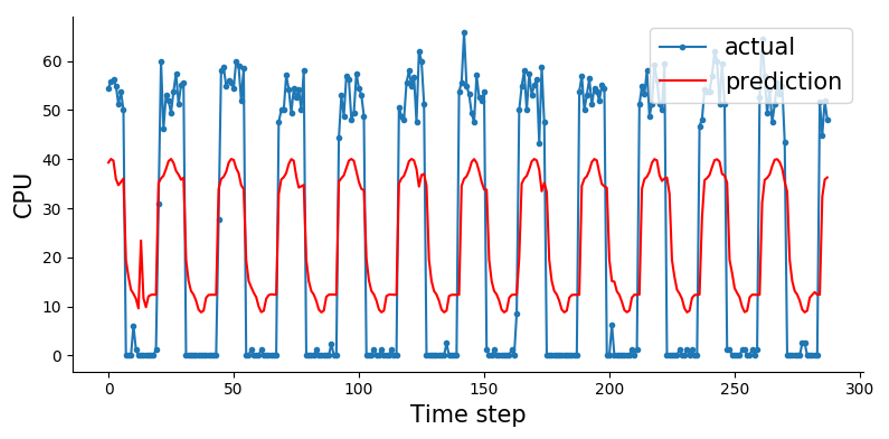
1. vm1
→ 데이터 흐름에 따른 예측
→ 변하는 흐름은 예측하지만 변동되는 값에 대해 정확한 예측이 어려움
→ 추후 데이터 양을 늘렸을 때 98% 예측 정확도(?)가 나옴
2. vm2
2-1.
→ 평일 오후를 제외하고 부하를 주지 않은 0에 가까운 값
→ 부하를 제공한 평일 데이터를 학습하더라도 직전 0값에 의해 예측을 진행하지 못함
→ 학습이 진행되면서 데이터에 대한 가중치가 갱신됨에 따라 이전 데이터의 가중치는 작아지는 특징
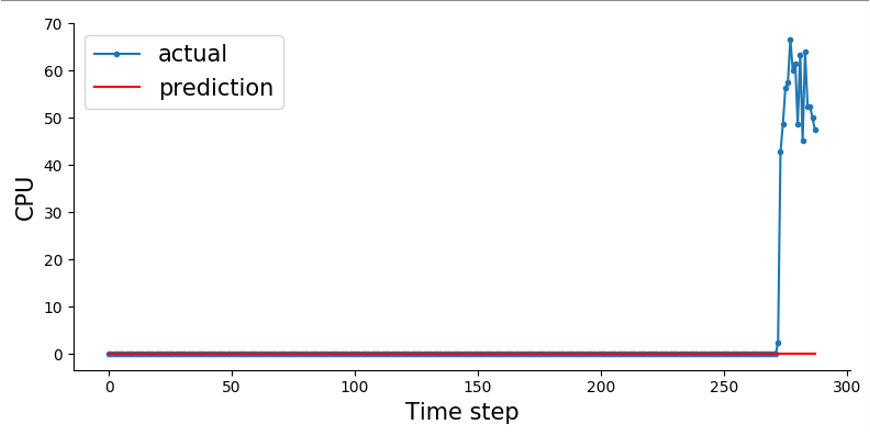
2-2.
→ 부하를 주지 않은 주말 데이터를 제외한 학습
→ 하루 예측
→ 평일 예측에 대해 흐름을 예측
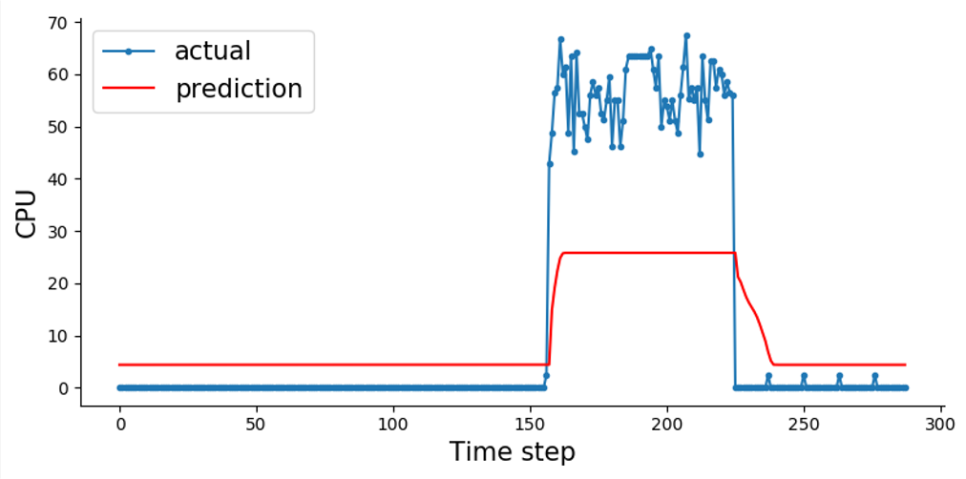
3. VM3
→ VM2와 동일
결론
→ 요일 혹은 평일, 주말을 구분하여 가중치 설정의 필요성
→ 학습 데이터 양의 문제일 가능성이 존재
학습 데이터 5일, 테스트 데이터 2일
학습 데이터 5일에 대한 정보가 한 주만 존재
딥러닝을 활용하여 특징을 추출하기에 부족함
→ 데이터 수집을 진행 및 가중치 설정을 진행함으로써 가능 여부를 판별 필요
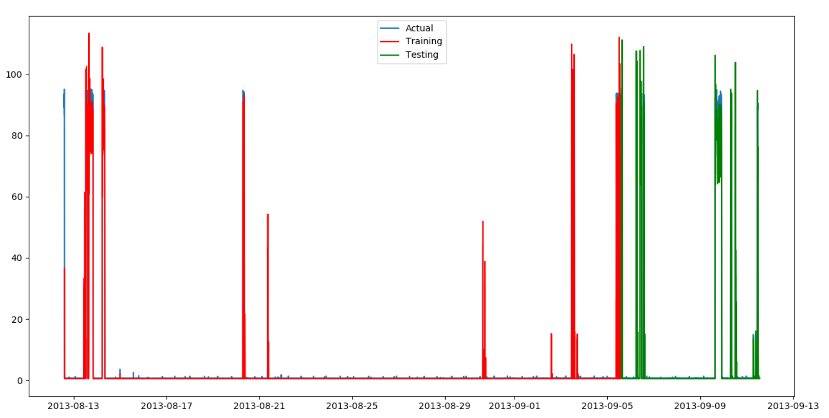
추후 가중치와 학습데이터 양을 늘려 실험해볼 생각이다.
오버피팅과 가중치를 잘 활용하면 괜찮은 결과가 나올 것 같다.
Leave a comment