
TAnoGAN : Time Series Anomaly Detection with Generative Adversarial Networks
시계열 데이터 이상탐지 논문 리뷰
※ 개인적으로 정리하고 싶은 부분 위주로 작성하였습니다.
들어가기전 기본 개념 정리
Time series Anomaly Detection
주어진 데이터가 타임시리즈로 구성되어 있으며, 특정 t 시점의 anomaly를 판단하는 것(unsupervised learning 방법론)
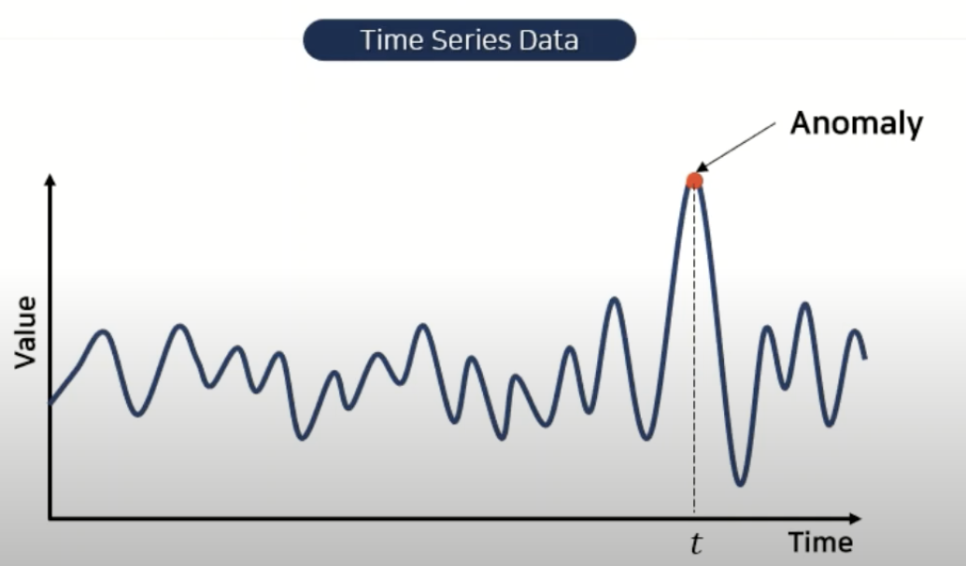
GAN 알고리즘 비교
AnoGAN : 일반적으로 이미지 데이터셋을 중심으로 진행한 것으로 generator, discriminator는 cnn구조로 되어있기 때문에 time series와 맞지 않는다.
MAD-GAN : TAnoGan과 비슷하지만 데이터 셋이 50~100만개, 즉, 소량의 데이터로 가능한지 검증은 되어 있지 않음
▶ TAnoGAN 장점
-
작은 size의 time series data 에 적용 가능
-
여러 도메인의 각기 다른 46개의 time series dataset에 대해 실험한 결과, 기존 방법론보다 좋은 일반화 성능을 보임
▶ Model
- label을 사용하지 않고 normal 데이터를 학습하여 새로운 데이터와 분포의 떨어짐을 계산하여 이상징후 판단을 진행 (unsupervised data이니까)
▶ 데이터 준비
- window size를 지정하고 sliding을 통해 생성된 데이터는 윈도우 사이즈만큼 시퀀스 리스트가 생기고 이를 input 데이터로 사용
▶ latent space
-
latent space로부터 노멀 데이터 생성하도록 모델을 생성 ( latent space : 벡터가 존재하는 공간) : 생성자는 input data를 벡터로 받음, 해당 벡터는 간단하게 normal distribution 에서 랜덤하게 추출된 값
-
새로운 데이터가 들어왔을 때, 새로운 데이터를 latent space에 보내줌
▶ 학습과정
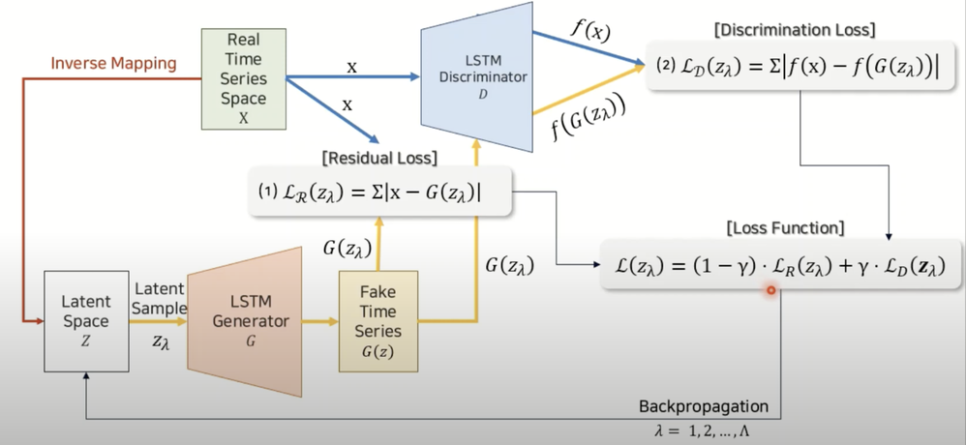
- Latent Space에서 랜덤 벡터 값인 Z를 받아 생성자를 통해 Fake Data를 생성한다.
-
생성자 G
-
생성자 G의 LSTM 구조는 충분한 매개변수를 확보하기 위해 Stack LSTM 사용
→ hidden unit수를 증가시킬수록 실험 결과가 좋은 것으로 확인
- 생성자로 생성된 Fake Data를 Fake, Real Data를 Real로 구분자 D를 통해 판별한다.
- 구분자 D
→ 진짜일 확률을 1, 가짜일 경우 0
→ 작은 데이터에 대해 크거나 깊은 d를 만들면 과적합이 일어나기 때문에 간단한 구조로 설계해야함
▶ 학습과정
1) G(z)에서 랜덤하게 선택된 벡터형태의 데이터가 input으로 들어감
2) G(z)에서 가져온 데이터는 fake data이기 때문에 Fake로 판별
3) 역전파를 통해 D를 업데이트(최적화 함수)
4) Real 데이터를 input으로 들어감
5) Real로 판단하기 위해 확률을 1로 두고 역전파를 통해 D를 업데이트
→ 출력 값과 0 값의 차이, 출력 값과 1 값의 차이 합이 D의 loss 값
출처 입력
- Real Data을 기반으로 역전파를 통해 G를 업데이트
→ 구분자 D를 속일만큼 real 데이터와 유사한 데이터를 생성하는게 목적
→ fake data가 1과 떨어진 정도를 통해 최소화하도록 G를 업데이트
-
Latent Space에서 랜덤하게 데이터 맵핑
-
이를 반복하여 업데이트 진행
-
마지막으로 업데이트 된 Z를 실제 데이터의 latent space로 매핑 확정하고, 확정된 데이터를 학습한 후 loss 값을 anomaly score로 사용함
▶ 실험환경 구성
-
G : 3개의 lstm layer로 구성, 히든 유닛은 늘림
-
D : 1개의 lstm layer로 구성, 히든 유닛은 100
→ nementa anomaly benchmark 데이터 사용
→ data 형태 : timestamp(2021-09-14 00:00:00)와 value(20, 32…)로 구성
→ 평가 : accuracy, precision, recall, F1-score, cohen kappa, AUROC
→ 8개정도 베이스라인 모델을 통해 비교 분석함(Isolation Forest, Gaussian, 각종 lstm, GAN 모델들)
▶ 결과
-
기본 anomaly detection 처럼 threshold 넘기면 이상판단,
-
recall 평가방법을 제외하고는 TAnoGAN이 성능이 높음
-
58개의 도메인이 있었는데 누적합을 보여주는 평가에서 도메인과 상관없이 TAnoGAN이 좋은 것을 알 수 있음
Leave a comment