
Zero-Shot Learning Through Cross-Modal Transfer
zero-shot learning 관련 논문 리뷰
기본개념
Zero-Shot Learning 이란?
“일반적인 사람의 능력을 학습으로 바꾼것이며 전이학습에서 발전된 기계학습의 한 종류이다.”
→ 즉, 데이터 간의 관계와 공통점으로 정답을 찾는 것!
특징
-
데이터가 없어도 양질의 패턴이나 결과를 도출할 수 있다.
-
label 값을 따로 지정하지 않아도 분류가 가능
Ex. 강아지 데이터를 통해 강아지 클래스를 학습하였는데 고양이 사진을 넣었다. 그럼 기존 인공지능의 경우는 분류하지 못하거나 유사도를 낮추며 강아지 클래스로 갈 것이다. 이러한 경우 제로샷 러닝은 고양이라는 클래스를 생성하는 것.
1.Introduction
Seen Class : 라벨링 되어 있는 클래스(학습 데이터)
Unseen Class : 라벨링 되어 있지 않은 클래스(테스트 데이터)
Seen Class : auto, horse, dog
Unseen Class : truck, cat
→ 테스트 데이터에서 truck이 인풋 데이터로 들어 갔을 경우 Seen Class 중 하나에 속하는지 새로운 클래스 truck에 속하는지 결정하는 모델을 보여주는 논문이라고 할 수 있음
→ 또한, 이미지가 아닌 단어를 통해 단어 유사성으로 zero-shot learning을 진행
2.Word and Image Representation
- representation : 상황에 따라 양질의 데이터를 표현하는 것
Ex. S라는 데이터 셋에서 A는 RGB이고, B는 HSV 포맷으로 인코딩을 진행하면 데이터는 같아도 두 가지 표현(representation)으로 나타낼 수 있는 것. 그래서 빨간 픽셀을 찾는다면 A에서 쉽게 찾고, 채도가 낮은 값을 찾는 다면 B를 사용하는 것이 쉬울 것이다.
-
사용된 방법
-
Representation을 위해 Distributional approach 방식을 사용
→ 단어가 분포적 특성 벡터로 표현(Co-occurrence 방식)
→ 단어 벡터는 50차원의 벡터로 초기화
Co-occurrence : 두 개 이상의 어휘가 일정한 range나 distance 내에서 함께 출현하는 현상(어휘 : 형태소, 합성어 등 단위로 의미를 부여할 수 있는 단위)
- 해당 부분을 실행하는 이유
→ 비슷한 맥락에 등장하는 단어들은 유사한 의미를 지니는 경향이 있어 이러한 추상적 정보를 얻기 위해 자연어 처리에서 자주 사용하고 있다.
해당 논문에서는..
→ 위키피디아 text를 사용하여 각각의 단어가 context에서 발생할 가능성을 예측. 즉, 단어 벡터를 학습
→ local context와 global document context를 모두 이용(통사적, 의미적 정보 분포를 모두 잡음)
3.Projecting Images into Semantic Word Spaces
- 이미지 학습
semantic relationship, class relationship을 학습시키기 위한 방법으로 단어 벡터 공간에 이미지 피쳐들을 투영
→ 투영을 시키게 되면 시각적으로 의미를 확장할 수 있음
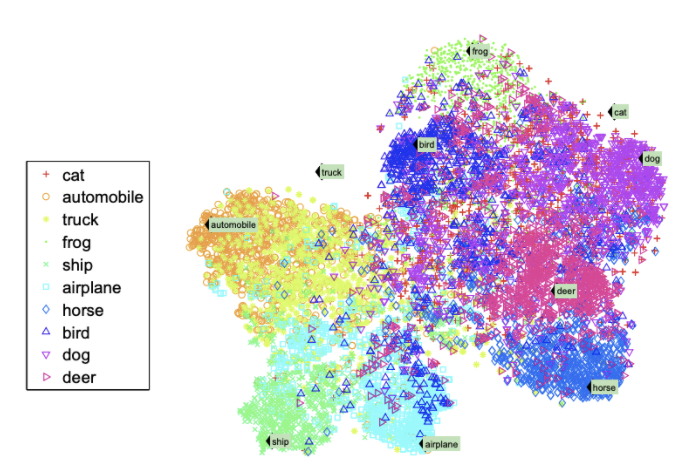
- 해당 방법을 통해 word vector와 image로 seen class, unseen class의 semantic space를 t-SNE 통해 2차원 축소 후 시각화한 것
→ 이미지가 존재하는 word vector들은 군집되어 있음
→ 이미지가 존재하지 않는 cat, truck의 경우 그렇지 않음
→ 의미적으로 유사한 벡터에 가깝게 위치하고 있음(ex. cat - dog, horse와 가깝지만 car, ship은 떨어져있다.)
→ 이런 것으로 zero-shot word vector로 분류
4. Zero-shot Learning Model
- zero-shot learning의 모델은 테스트 셋 이미지에 대해 seen, unseen 클래스에 대한 y일 확률을 예측하는 것
→ 이를 위해 semantic vectors를 사용하고, 이상치 탐지를 적용하여 클래스 분류를 처리함
- y 가 seen인지 unseen인지 판별하기 위해 다음과 같은 식으로 확률을 계산
4.1. 신규 데이
터 탐지 전략
→ 학습 데이터에는 unseen 데이터가 없기 때문에 클래스 확률을 구할 수 없음
→ 하지만 앞에서 설명된 것과 같이 semantic region에 있을 것임
→ 따라서, 이상치 탐지로 seen, unseen을 구분함
- 이상치 탐지는 2가지 사용(둘 다 semantic vector가 매핑 된 학습 이미지의 매니폴드를 계산하는 방법임)
manifold : 데이터를 공간에 뿌리면 sample들을 잘 아우를수 있는 subspace가 있을 것이라는 가정에서 학습을 진행하는 방법
- 각 클래스 마다 등거리 변환된 정규분포 사용(등거리 변환 : 거리 공간 사이 함수)
-
각 seen 클래스에 대해 정규분포를 구하고, 이 정규분포는 semantic word vector를 평균화하여 합한것을 공분산으로 갖게됨
-
threshold를 설정하고, threshold 이하면 이상(1)으로 표시하며, unseen으로 판별함
-
해당방법은 이상치에 대한 실제 확률 값을 도출하지 않음
- 이를 보안하고자 seen과 unseen에 대한 weighted combinated classifiers를 사용해 클래스에 대한 조건부 확률을 구함
-
seen 클래스의 학습 데이터 중 테스트 셋 semantic vector에 대해 knn을 이용
-
k를 context set으로 한 다음 이미지 테스트 셋과의 probabilistic set distance를 유클리드 거리를 통해 구함
▶ seen 클래스를 위한 거리확률
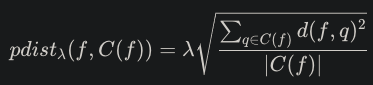
- 이상치에 비례하는 lof 값을 구함(이상값 찾기(local outlier factor, lof) : 밀도기반으로 이상 값을 찾는 알고리즘(밀도가 낮은 것들)
▶ lof
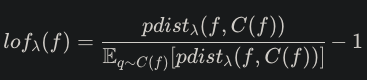
-
실제 확률을 구하기 위한 정규화 진행
-
seen 클래스의 학습 데이터의 lof값에 대한 표준 편차
▶ lof 표준 편차
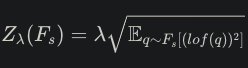
- lof, 정규화를 통해 local outlier probability를 구함 : seen, unseen에 대한 실제 확률
▶ 실제 확률
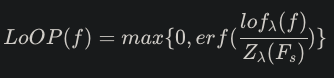
4.2. 분류
seen 클래스는 아무 분류 모델이나 사용해도 상관없지만 해당 논문에서는 softmax classifier 사용
unseen 클래스는 novel class word vectors에 isometric gaussian을 가정하여 likelihood에 따라 클래스 분류 → zero-shot learning
5. 실험
-
사용 데이터 : CIFAR-10 → 10개의 클래스로 구성(비행기, 개, 고양이 등) → 500개씩 / total 5000개
-
vector : feature vector는 12,800차원의 벡터로 변환(기존 변환 방법 사용) / word vector는 50차원의 word vector set 사용(기존에 타 논문에서 사용된 학습된 벡터를 가져와서 씀)
10개중 2개의 클래스를 unseen으로 가정하여 사용(test에만 넣는다는것)
5.1. seen과 unseen의 클래스 분류
- seen class를 분류
위에서 말한바와 같이 softmax classifier사용
8개에 대한 분류 정확도를 평가한 결과 10개의 클래스에 대해 분류한 평가 결과와 성능이 비슷
- softmax classifier : 인공신경망에 다른 층 없이 softmax 층만 붙인 것이다. logistic regression을 class 수만큼 실행하고, 이 값들을 softmax 층에 통과시켜 분류한 것
- unseen class를 분류
isometric gaussian을 이용하여 분류한다.
unseen class의 word vector와 맵핑된 이미지 벡터 사이에서 거리가 가장 가까운 클래스로 분류를 해주는 것
결국은 앞서말한 사이공간 벡터를 통해 유사하게 밀집되어있는 것을 정규화해서 분류한다는 것
5.2. seen, unseen을 함께 학습하여 에측
위의 실험은 seen, unseen 각각 분류를 진행
해당 절에서는 함께 test하여 예측을 진행해보고자 함
위 실험을 통해 seen, unseen 클래스 분류는 진행되어 있는 상태임
분수(부분이 전체에서 차지하는) 정도에 따라 두 분류기가 다름
seen 데이터의 경우 LoOP 모델을 사용하면 좋고, Unseen 데이터의 경우 Gaussian 모델을 고려할 수 있음
Gaussian의 경우 제한점이 없고 분수가 상승해도 비교적 unseen을 잘 분류함
LoOP 모델은 이상치 분류 모델이기 때문에 메인포드 평면 상에 넓게 퍼져있는 unseen 데이터를 제대로 분류하지 못하면서 분수가 커질수록 seen을 잘 분류함
→ 결론은 Seen 성능을 더 잡거나 Unseen 성능을 더 잡는가에 따라 threshold 조절하고 분류기를 선택하면 좋을 것 같음
5.3. zero-shot classes with distractor words
현실적으로 봤을 때 라벨링 되어있고 분류가 되어있는 것이 아닌 unseen의 데이터가 많을 것이다.
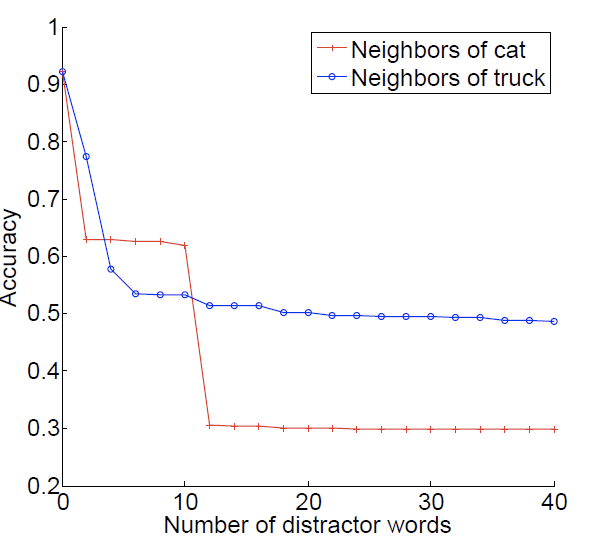
두가지 상황을 가정
-
무작위 word vector를 distractor words로 추가하여 unseen 데이터의 정확도를 측정(distractor word는 기존 양질의 데이터에 넣어서 약간 어지럽히다? 초점을 흐리게한다? 그런뜻으로 추가제공하지만 이게 잘 분류될 애들을 더럽게 만들어서 진행한다는 느낌으로 사용하는듯)
-
unseen 클래스와 word space 상 거리가 가까운 단어를 distractor words로 추가하여 측정
해당 논문에서 제안하는 모델은 기본적으로 이미지 데이터를 word space 상에 맵핑하고, 가까운 calss의 word vector를 찾아 분류하기 때문에 클래스가 전혀 아닌 word vector가 추가되었을 때 어째되는지 실험을 한 것
cat의 경우 rabbit, kitten, mouse와 같은 단어를 추가적으로 제공하여 실험
실험 결과
-
무작위로 word vector을 추가한 경우 성능이 저하되지는 않음
-
unseen과 비슷한 단어를 추가한 경우 일정 개수 추가 시에 성능이 저하되다가 수렴(맵핑이 잘 이루어진 것임)
해석하자면, cat과 kitten은 같은 의미를 가지는 단어이고 이는 word space에서 비슷한 곳에 위치해 있을 거임. 이미지를 맵핑했을 때 둘 사이에 분류되는 이미지가 있을 것임
word vector 자체에도 거리가 있으면 이미지도 거리가 있을 거임. 그렇기 때문에 성능에 영향을 끼치는 정도는 아닌듯
- 결론
딥러닝을 활용하여 단어 및 이미지를 이용하여 제로샷 분류 모델을 제안
워드 임베딩을 통해 만들어진 벡터들이 나타내는 표상은 이미지와 텍스트간의 지식 전달을 가능하게 함
Leave a comment